

I am currently in the process of completing my masters dissertation. It’s a large document which I have spent the last year or so writing and I am pretty happy with how it has all turned out. I’ll be sharing more about the contents and findings of the thesis in the next little while.
As I was editing the thesis I thought it might be interesting to try and visualize how referencing occurred within the document. I had to double check all of the references anyhow, so I thought I would try to make the process more interesting by: programmaticly extracting all of the in text references; creating a list of references and where they occur in the document (by chapter); and then trying to visualize the connections between references and chapters throughout the entire document.
After mentioning this to a number of my colleagues, I decided to document the process as it generated some interest. Also I find it useful to document the process in case I need to do it again later. Credits to my colleague Andrew Deacon for helping me formulate this process.
We are going to extract all of the references in the document. Start by copying all of the text from your document into an advanced text editor such as Notepad++. You can then use the find and replace function within Notepad++ to identify the parenthesis which surrounds each reference. We want to get each reference on its own line so we can generate a list. Open the ‘Find’ utility and turn on the ‘Regular expression’ search mode in the bottom right of the window.
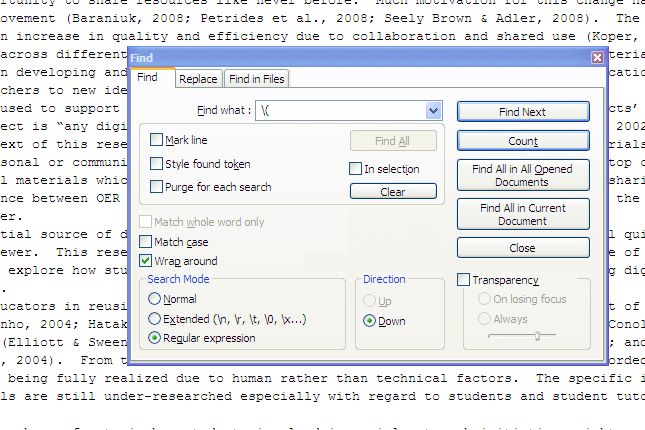
The regular expression search will enable you to search and replace with paragraph breaks. Start by searching for ‘(‘ to identify the opening parenthesis. The backslash is required as an escape character because the regular expression search is turned on. You can now find and count the number of opening parenthesis in your document. We want to have each opening parenthesis on a new line, so replace the ‘(’ with ‘rn(‘.
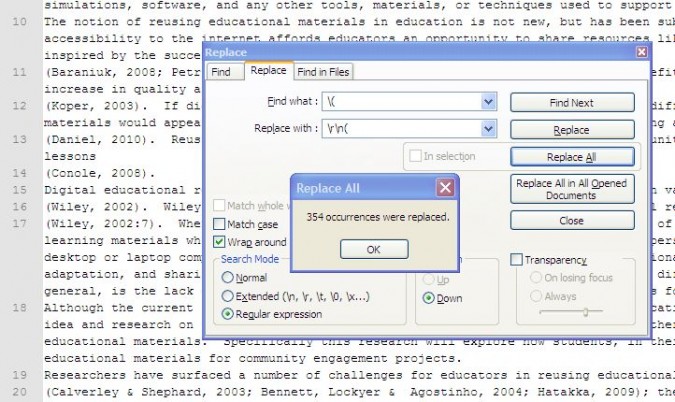
Now we can do the same for the trailing parenthesis. So do another find and replace this time replace ‘)’ with ‘)rn’. Now each in text reference should be on its own line.
Now search again this time in normal search mode for an ‘(’, and hit the button ‘Find All in Current Document’. You should be presented with a list of search results with each in text reference that can be easily copied to Excel.
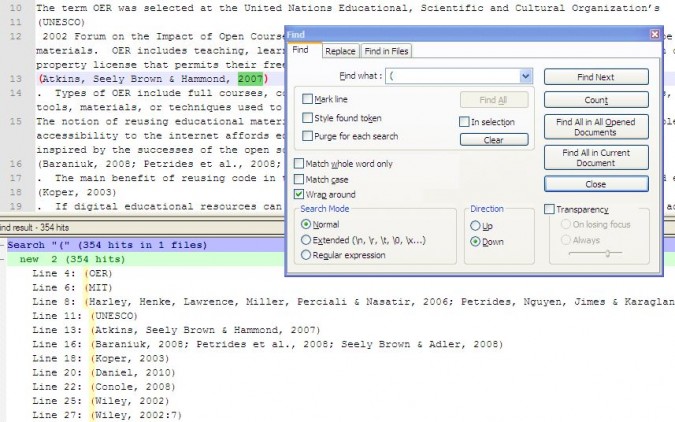
You will still have to sort out the combined references, et al’s, remove the acronyms, and non-reference parenthesis occurrences. I also stripped the parenthesis from the text. Keep the line number so you can determine which chapter each reference occurred within. If you back to Notepad++ you can grab the line numbers where each section begins and end, mine was quite simple as I only had five chapters.
CH1 lines: 1-132
CH2 133-638
CH3 639-881
CH4 882-1394
CH5 1395-1479
Once you have cleansed the data you should have a clean list of references. You can use a VLOOKUP to bring in the chapter numbers in Excel. This process was also very useful for verifying my references and ensuring I used the full reference in a multi author (+3) paper when it first occurred in text.
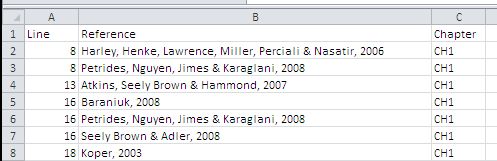
You can then create a pivot table which will show the references per chapter also showing how many times each paper was referenced.

Now you can take columns A and B shown above and drop them into something like NodeXL to visualize the connections between your reference occurrences (you will have to copy down the ‘CH1’ text). You can use the ‘Totals’ column to make the connecting lines bigger where a reference was used multiple times. I use the Total field as the Edge Width connecting the reference to the chapter. You will also want to make the chapter nodes a larger more distinct object, I have used coloured discs. I have also run a grouping algorithm on the dataset which identifies the references which best group together and applies a colour for each node.
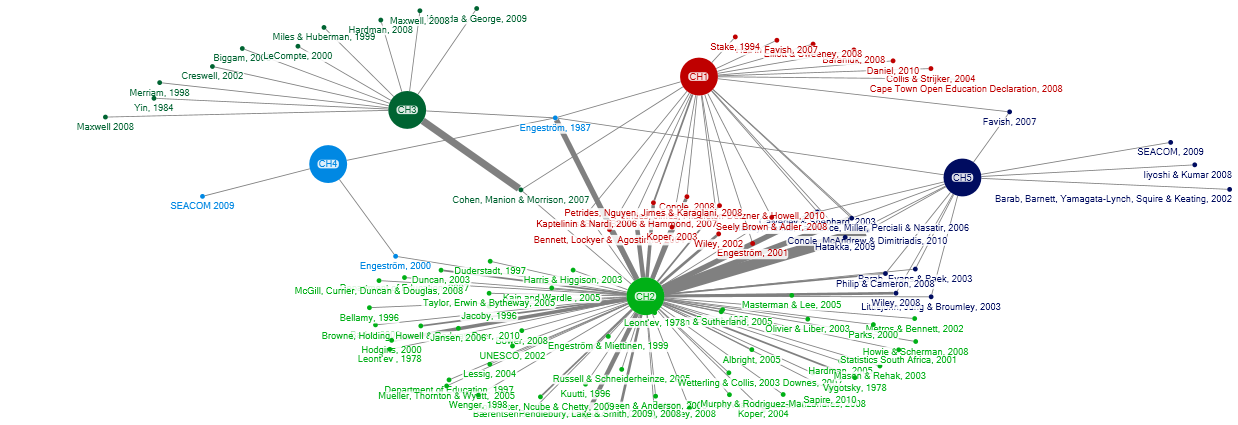
The visual shows the references used in my thesis as they occurred within chapters, and were reused within other chapters. The central literature which I use to support my thesis ends up in the middle of the image (the central red text).
Looking back, this is quite a useful visual of how I constructed my thesis and how certain resources were woven into the various chapters of my research. Chapter 2 naturally contains the most references as it forms my literature review. The literature which ultimately becomes useful in my study is used again in Chapter 5 my conclusion; as well as being mentioned in Chapter 1 as I introduce the study. Two key resources, Engëstrom, 1987 (theoretical framework) and Cohen, Manion & Morrison, 2007 (research design) are used within Chapter 2 and 3, as I explain and then localise their application in the study.
I am toying with the idea of including this in front of the bibliography in my thesis submission. Think it might be useful or actually annoy an external examiner?
The most central literature is referenced below:
Conole, G., McAndrew, P. & Dimitriadis, Y. (2010). The role of CSCL pedagogical patterns as mediating artefacts for repurposing Open Educational Resources. In: Pozzi, Francesca and Persico, Donatella eds. Techniques for Fostering Collaboration in Online Learning Communities: Theoretical and Practical Perspectives. Hershey, USA: IGI Global.
Cohen, L., Manion, L & Morrison, K. (2007). Research methods in education. 6th edition. London: Routledge.
Engeström, Y. (1987). Learning by expanding: An activity-theoretical approach to developmental research. Helsinki: Orienta-Konsultit.
Harley, D., Henke, J., Lawrence, S., Miller, I., Perciali, I., Nasatir, D. (2006). Use and Users of Digital Resources: A Focus on Undergraduate Education in the Humanities and Social Sciences. Center for Studies in Higher Education (CSHE), University of California, Berkeley.
Hatakka, M. (2009). Build it and They Will Come? – Inhibiting Factors for Reuse of Open Content in Developing Countries. The Electronic Journal of Information Systems in Developing Countries. EJISDC (2009) 37, 5, 1-16.